I usually write about recent scientific publications that I find interesting and important, usually in the general area of biology. My goal is to promote scientific literacy and an awareness of the many remarkable advances in all areas of science. I try to provide some background context for the published study and then summarize the salient findings. As I’ve written these blogs over the last few years, I’ve realized that my readers may lack the foundational knowledge that underpins much of the biological literature. To further my goal of educating the public, I’ve decided to also write posts that focus on teaching concepts and principles. I’ll still write about current publications but will periodically post my “Understanding XXX” series. Each series will address a specific area or topic in biology and will be a mini-course on that subject. My first series is Understanding Molecular Biology. I hope you enjoy these blogs and find them useful learning tools. If there are topics you’d like me to address please let me know and I’ll add them to my list.
All life on Earth uses DNA as the genetic material, with exception of some viruses that use a related molecule called RNA which we will discuss in a future blog. DNA stands for DeoxyriboNucleic Acid and is a long polymer chain made up of four different subunits (abbreviated A, C, G, and T) called deoxynucleotides (Fig. 1).

The deoxynucleotides are the basic building blocks of DNA, and each deoxynucleotide is in turn composed of three components: a phosphate group, a sugar molecule (called deoxyribose), and a molecule called a base (Fig. 2).
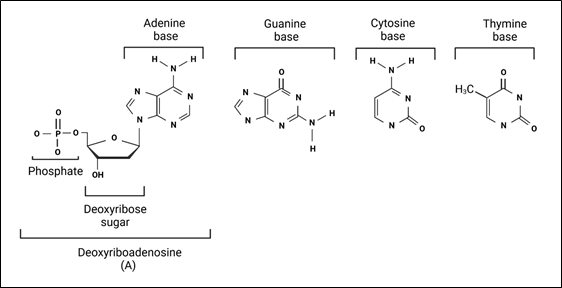
There are just 4 bases in DNA, 2 purines (adenine [A] and guanine [G]) and 2 pyrimidines (cytosine [C] and thymine [T]). Just like individual letters of the alphabet are the building blocks of words, in the language of DNA the 4 bases (A, G, C, and T) are the letters of the genetic alphabet.
Other than some DNA viruses, the DNA of other life forms is a double-stranded molecule that forms the canonical double helix (Fig. 3A).
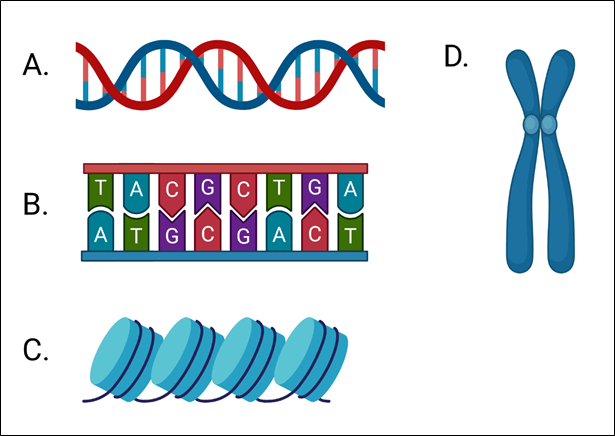
The two strands are held together by bonding between deoxyribonucleotides on opposite strands. Importantly, the two strands of the double helix have a complementary sequence: an A base always pairs with a T base and a C base always pairs with a G base (Fig. 3B). This complementary pairing means that either strand can serve as a template for replicating the other strand. The complementarity of base pairing is also critical for the production of messenger RNA (mRNA) which will be described in a future blog.
In the cell, DNA is associated with many proteins, including a family of proteins called histones which wrap the DNA into structures called nucleosomes (Fig. 3C); histone-bound DNA is referred to as chromatin. Wrapping and compacting the DNA using proteins is important for fitting the extremely long DNA molecule into the tiny space of a cell. In addition, the human genome is not a single piece of chromatin but instead consists of 23 pieces called chromosomes. For our somatic cells (every cell except for egg and sperm cells), each chromosome exists in two copies, one copy comes from our mother and one from our father (Fig. 3D). Because we have 2 copies of each chromosome this is called a diploid genome. Egg and sperm cells have haploid genomes because these specialized cells only contain one copy of each chromosome. When a sperm fertilizes an egg the resulting cell now has both the maternal and paternal chromosome copies and is diploid. That fertilized egg can now grow and divide to give rise to all the parts of the body. Every time the cells divide the entire chromosome content must be duplicated so that each of the two new daughter cells receives the complete genome. In the next blog, I’ll discuss DNA replication and its consequences.

Leave a comment